
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 리액트
- 유튜브 클론코딩
- 모던 자바스크립트 Deep Dive
- 보조저장장치
- MongoDB
- 제어유니트
- 마이크로명령어
- 유튜브클론코딩
- 깃허브 로그인
- pug
- react
- 자바스크립트
- 자바스크립트 배열
- 자료구조
- mongoose
- Session
- 연결자료구조
- CPU
- Nodemon
- JavaScript
- cookie
- 프론트엔드
- 제어유닛
- 후위표기법연산
- 후위표기법변환
- 컴퓨터 구조
- node.js
- 컴퓨터 구조론
- 표현식과 문
- Express
- Today
- Total
909 Devlog
[자료구조] - 연결 자료구조와 연결 리스트 본문
👋 본 글은 "C로 배우는 쉬운 자료구조" 책을 읽고 요약, 정리한 글입니다.

책 구매 링크에서 책을 확인하실 수 있습니다.
🎯 1. 연결 자료구조와 연결 리스트의 이해
📌 1 - 1. 연결 자료구조의 개념
연결 자료구조란? : 연속한 물리 주소에 의해 원소 순서를 표현하는 것이 아닌, 각 원소에 저장되어 있는 다음 원소의 주소(링크)에 의해 순서가 연결되는 구현 방식
연결 자료구조의 원소는 연결될 다음 원소에 대한 주소를 저장하므로 <원소, 주소> 단위로 구성됨
이를 노드라고 하며 원소값을 저장하는 데이터 필드와 링크 필드로 구성된다.
- 데이터 필드는 원소의 형태에 따라 한 개 이상으로 구성할 수 있다.
- 링크 필드는 포인터 변수를 사용하여 주소값을 저장하며, 포인터 또는 링크 또는 참조라고도 한다.
| 구분 | 순차 자료구조 | 연결 자료구조 |
| 메모리 저장 방식 | 필요한 전체 메모리 크기를 계산하여 할당하고, 할당된 메모리의 시작 위치부터 빈자리 없이 자료를 순서대로 연속하여 저장함 | 노드 단위로 메모리가 할당되며, 저장 위치의 순서와 상관없이 노드의 링크 필드에 다음 자료의 주소를 저장함 |
| 연산 특징 | 삽입, 삭제 연산 후에도 빈자리 없이 자료가 순서대로 연속 저장되어, 변경된 논리적인 순서와 저장된 물리적인 순서가 일치함 | 삽입, 삭제 연산 후 논리적인 순서가 변경되어도 링크 정보만 변경되고 물리적 위치는 변경되지 않음 |
| 프로그램 기법 | 배열을 이용한 구현 | 포인터를 이용한 구현 |
연결 리스트는 노드를 연결하는 방식에 따라
- 단순 연결 리스트
- 원형 연결 리스트
- 이중 연결 리스트
- 이중 원형 연결 리스트
로 나눌 수 있다.
아래에서 하나씩 살펴보도록 하자.
📌 1 - 2. 연결 리스트의 이해
이전 장에서 보았던 선형 리스트로 일주일을 표현하는 방법은 다음과 같다.
| [0] | [1] | [2] | [3] | [4] | [5] | [6] |
| 월 | 화 | 수 | 목 | 금 | 토 | 일 |
배열 원소 일곱 개를 사용하여 연속적인 순차 구조를 메모리게 표현하였다.
이번에 살펴볼 연결 리스트의 모습은 다음과 같다.
(아래 그림에 나와있는 것처럼 데이터가 순서대로 저장되어 있지 않다. (논리적 순서와 물리적 순서가 일치하지 않는다.))
week 노드는 연결 리스트의 시작을 가리키는 포인터 변수이다.
week은 "월" data를 가진 노드를 가리키고, "월" data를 가진 노드는 "화" data를 가진 노드를 가리킨다 이 흐름을 계속 따라가다 보면 link가 NULL인 노드에 다다르게 되는데, link가 NULL인 노드가 연결 리스트의 마지막 요소이다.
만약 요소가 하나도 없는 공백 연결 리스트라면 포인터 변수 week에 NULL을 저장한다.

연결 리스트의 값을 액세스 하려면 포인터의 점 연산자( . )를 사용해 액세스 한다.
예를 들어 "월" data를 얻으려면 week.data를 사용해야 하고, "화" data를 가진 노드를 가리키는 링크를 얻으려면 week.link를 사용해야 한다.
또, "화" data를 얻으려면 week.link.data를 통해 얻을 수 있고, "수" data를 가진 노드를 가리키는 링크를 얻으려면 week.link.link를 통해 얻을 수 있다.

위에서 봤던 노드를 C언어로 표현하면 다음과 같이 구조체로 정의할 수 있다.
typedef struct Node {
char data[4];
struct Node* link;
}
🎯 2. 단순 연결 리스트
📌 2 - 1. 단순 연결 리스트의 개념
단순 연결 리스트 : 노드의 링크 필드가 하나이며, 링크 필드는 다음 노드와 연결되는 구조
📌 2 - 2. 단순 연결 리스트에서의 삽입 연산
단순 연결 리스트에 새 노드를 삽입하는 방법은 다음과 같다.
- 삽입할 노드를 준비한다.
- 새 노드의 데이터 필드에 값을 저장한다.
- 새 노드의 링크값을 지정한다.
- 리스트의 앞 노드에 새 노드를 연결한다.
week -> 월 노드 -> 수 노드 형태로 구성되어있는 연결 리스트에 화 노드를 삽입해 보자.
(data + link는 하나의 노드이다.)
| week | data | link | data | link |
| ➡️(월 노드의 주소) | 월 | ➡️ (수 노드의 주소) | 수 | NULL |
먼저 삽입할 노드를 준비한다.
| data | link |
새 노드의 데이터 필드에 값을 저장한다.
| data | link |
| 화 |
새 노드의 링크값을 지정한다.
| data | link |
| 화 | ➡️(수 노드의 주소) |
리스트의 앞 노드에 새 노드를 연결한다.
| week | data | link | data | link | data | link |
| ➡️(월 노드의 주소) | 월 | ➡️ (화 노드의 주소) | 화 | ➡️ (수 노드의 주소) | 수 | NULL |
선형 순차 리스트와 달리 단순 연결 리스트에서는 삽입 연산을 할 때 물리적인 순서를 유지하기 위해 원소들을 이동시키지 않아도 된다. 이처럼 연결 자료구조는 링크 필드의 포인터값에 대한 연산만으로 삽입 연산을 쉽게 수행할 수 있다.
📌 2 - 3. 단순 연결리스트에서의 삭제 연산
단순 연결 리스트에서 노드를 삭제하는 방법은 다음과 같다.
- 삭제할 노드의 앞 노드를 찾는다.
- 앞 노드에 삭제할 노드의 링크 필드값을 저장한다.
- 삭제한 노드의 앞 노드와 삭제한 노드의 다음 노드를 연결한다.
아래와 같은 연결 리스트 구조에서 "화" 노드를 삭제해 보자.
| week | data | link | data | link | data | link |
| ➡️(월 노드의 주소) | 월 | ➡️(화 노드의 주소) | 화 | ➡️ (수 노드의 주소) | 수 | NULL |
삭제할 노드의 앞 노드를 찾는다.
| week | data | link | data | link | data | link |
| ➡️(월 노드의 주소) | 월 | ➡️ (화 노드의 주소) | 화 | ➡️ (수 노드의 주소) | 수 | NULL |
앞 노드에 삭제할 노드의 링크 필드값을 지정한다.
| week | data | link | data | link | data | link |
| ➡️(월 노드의 주소) | 월 | ➡️ (수 노드의 주소) | 화 | ➡️ (수 노드의 주소) | 수 | NULL |
삭제한 노드의 앞 노드와 삭제한 노드의 다음 노드를 연결한다.
| week | data | link | data | link |
| ➡️(월 노드의 주소) | 월 | ➡️ (수 노드의 주소) | 수 | NULL |
단순 연결 리스트의 삭제 연산에서도 원소들이 물리적으로 이동하지 않고 링크 필드의 포인터값에 대한 연산을 수행한다.
📌 2 - 4. 단순 연결리스트의 알고리즘과 프로그램
단순 연결 리스트에서 노드를 삽입할 때, 삭제할 때, 탐색할 때 사용하는 알고리즘을 살펴보자
먼저 삽입의 경우, 첫 번째 노드, 중간 노드, 마지막 노드 중 어디에 삽입하느냐에 따라 세 가지 알고리즘으로 구분하여 살펴본다.
리스트에 첫 번째 노드로 삽입하는 알고리즘
첫 번째 노드로 삽입하려면 다음 순서를 따른다
- 새 노드 생성
- 새 노드에 데이터 할당
- 새 노드에 기존 리스트 헤더가 가리키던 주소 할당 (삽입하기 전, 기존의 첫 번째 노드의 주소)
- 리스트 헤더에 새 노드의 주소 할당
아래 연결 리스트에 첫 노드를 삽입해 보자.
| week | data | link | data | link |
| ➡️ (화 노드의 주소) | 화 | ➡️ (수 노드의 주소) | 수 | NULL |
먼저 삽입할 노드를 준비한다.
| data | link |
삽입할 노드에 데이터를 할당한다
| data | link |
| 월 |
새 노드에 리스트 헤더가 가리키던 주소 할당 ('화' 노드를 가리키고 있었음)
| data | link | data | link | data | link |
| 월 | ➡️ (화 노드의 주소) | 화 | ➡️ (수 노드의 주소) | 수 | NULL |
마지막으로 리스트 헤더에 새로 추가한 노드의 주소를 할당한다.
| week | data | link | data | link | data | link |
| ➡️ (월 노드의 주소) | 월 | ➡️ (화 노드의 주소) | 화 | ➡️ (수 노드의 주소) | 수 | NULL |
리스트 중간에 노드를 삽입하는 알고리즘
리스트 중간에 노드를 삽입할 때는 중간에 리스트가 비어있는지 확인해야 한다.
만약 리스트가 비어있다면, 첫 번째 노드로 삽입하는 알고리즘과 같다.
따라서 다음 순서를 따른다.
- 새 노드 생성
- 새 노드에 데이터 할당
- if(리스트가 비어있는가?)
- true일 경우
- 리스트 헤더에 새 노드의 주소 할당
- 새 노드의 link에 NULL 할당
- false일 경우
- 새 노드의 link에 이전 노드의 link 할당
- 이전 노드의 link에 새 노드의 주소 할당
- true일 경우
다음과 같은 2개의 연결 리스트가 있을 때의 경우를 살펴보자
1.
| week | data | link | data | link |
| ➡️ (월 노드의 주소) | 월 | ➡️ (수 노드의 주소) | 수 | NULL |
2.
| week |
| NULL |
먼저 삽입할 새 노드를 생성한다.
| data | link |
삽입할 새 노드에 데이터를 할당한다.
| data | link |
| 화 |
이제 리스트가 비어있는지 확인한다
리스트가 비어있는 경우인 2번 리스트를 먼저 살펴보자.
새로 삽입할 노드에 데이터까지 할당했으니
이제 리스트 헤더에 새로 삽입할 노드의 주소를 할당한다.
| week | data | link |
| ➡️ (화 노드의 주소) | 화 |
그 후 새로 삽입할 노드의 link에 NULL을 할당한다.
| week | data | link |
| ➡️ (화 노드의 주소) | 화 | NULL |
이제 리스트에 요소가 있는 경우인 1번 리스트를 살펴보자.
새 노드의 link에 이전 노드의 link를 할당해야 한다.
| week | data | link | data | link | data | link |
| ➡️ (월 노드의 주소) | 월 | ➡️ (수 노드의 주소) | 화 | ➡️ (수 노드의 주소) | 수 | NULL |
그 후 이전 노드의 link에 새로 삽입할 노드의 주소를 할당한다.
| week | data | link | data | link | data | link |
| ➡️ (월) | 월 | ➡️ (화 노드의 주소) | 화 | ➡️ (수 노드의 주소) | 수 | NULL |
리스트 마지막에 노드로 삽입하는 알고리즘
이번 알고리즘 또한 중간에 리스트가 비어있는지 확인해야 한다.
만약 리스트가 비어있다면, 첫 번째 노드로 삽입하는 알고리즘과 같다.
따라서 다음 순서를 따른다.
- 새 노드 생성
- 새 노드에 데이터 할당
- 새 노드의 link에 NULL 할당
- if(리스트가 비어있는가?)
- true일 경우
- 리스트 헤더에 새 노드의 주소를 할당한다
- false일 경우
- temp에 리스트 헤더가 가리키는 노드를 임시로 저장하고
- while문을 통해 temp의 link가 NULL일 때까지(마지막 노드일 때까지) temp를 계속 temp.link 처리한다.
- while문을 돌고 나온 temp의 link에 새 노드의 주소를 할당한다.
- true일 경우
리스트가 비어있는 경우는 위에서 비슷하게 다루었기 때문에 스킵하고, 리스트에 다른 노드들이 이미 있는 경우를 살펴보자.
아래 리스트에 '수' 노드를 삽입하려 한다.
| week | data | link | week | link |
| ➡️ (월 노드의 주소) | 월 | ➡️ (화 노드의 주소) | 화 | NULL |
먼저, 새 노드를 생성한다.
| data | link |
새 노드에 데이터를 할당한다.
| data | link |
| 수 |
새 노드의 link에 NULL을 할당한다.
| data | link |
| 수 | NULL |
if문을 통과 (삽입할 리스트에 이미 요소가 있음)
temp 노드에 헤더가 가리키는 값을 임시로 저장한다.
(아래는 temp 노드이고, 헤더가 가리키던 첫 번째 요소를 임시로 저장했다.)
| data | link |
| 월 | ➡️ (화 노드의 주소) |
while문을 통해 temp의 link가 NULL이 될 때 까지 temp를 temp.link 처리한다.
(위에서 봤던 리스트는 노드의 개수가 2개라서, while 루프를 한 번만 돈다.)
| data | link |
| 화 | NULL |
while문을 돌고 나온 temp의 link에 새 노드의 주소를 할당한다.
| week | data | link | data | link | data | link |
| ➡️ (월 노드의 주소) | 월 | ➡️ (화 노드의 주소) | 화 | ➡️ (수 노드의 주소) | 수 | NULL |
노드를 삭제하는 알고리즘
이제 노드를 삭제하는 알고리즘을 살펴보자.
해당 알고리즘을 수행하기 위해서는 삭제할 노드의 이전 노드를 알고 있어야 한다.
노드 삭제 알고리즘은 시작부터 바로 리스트가 비어있는지 검사하고,
삭제할 요소가 있는지 또 검사해야 한다.
- if(리스트가 비어있는가?)
- true일 경우
- 에러메시지를 출력한다. (이미 리스트에 아무 노드도 없는데 삭제하려 했으니)
- false일 경우
- old라는 임시 변수에 이전 노드의 링크 (삭제할 노드의 주소)를 임시로 저장한다.
- if(old가 NULL 인가? (삭제할 노드가 존재하는가?))
- true일 경우
- 그냥 리턴한다 (아무런 동작 없이 알고리즘을 종료한다.)
- false일 경우
- 삭제할 노드(old)의 link를 이전 노드의 link에 할당한다.
- 삭제할 노드의 메모리 공간 점유를 해제한다.
- true일 경우
- true일 경우
이번에는 리스트에 요소가 존재하고, 삭제할 요소도 존재하는 아래 경우를 살펴보자.
| week | data | link | data | link | data | link |
| ➡️ (월 노드의 주소) | 월 | ➡️ (화 노드의 주소) | 화 | ➡️ (수 노드의 주소) | 수 | NULL |
'화' 노드를 삭제해 보자.
if(리스트가 비어있는가?)를 통과하고, old에 삭제할 노드의 이전 노드의 link를 임시로 저장한다.
| data | link |
| 화 | ➡️ (수 노드의 주소) |
if(old가 NULL 인가?)를 통과하고, 삭제할 노드의 link를 이전 노드의 link에 할당한다.
| week | data | link | data | link | data | link |
| ➡️ (월 노드의 주소) | 월 | ➡️ (수 노드의 주소) | 화 | ➡️ (수 노드의 주소) | 수 | NULL |
삭제할 노드의 메모리 공간 점유를 해제한다.
| week | data | link | data | link |
| ➡️ (월 노드의 주소) | 월 | ➡️ (수 노드의 주소) | 수 | NULL |
노드를 탐색하는 알고리즘
이제 단순 연결리스트의 마지막 알고리즘인 탐색 알고리즘을 살펴보자.
탐색 알고리즘은 데이터를 매개변수로 받아서 해당 데이터를 찾을 때까지 while을 반복하는 작업을 수행하게 된다.
순서대로 살펴보자면
- temp에 리스트 헤더가 가리키던 노드를 임시로 할당한다.
- while(temp가 NULL인가?) 문을 수행한다.
- 루프를 돌 때마다 if(temp.data가 매개변수로 받은 데이터 x와 같은가?)를 계속 검사한다. 만약 데이터가 맞다면 해당 노드 (temp를 반환하고 알고리즘을 종료한다)
- if문에 걸리지 못하고 else로 넘어오게 되면 temp에 temp.link 값(다음 노드)을 할당한다.
- 만약 while을 다 돌고도 노드를 탐색하지 못했다면 temp(NULL)을 반환한다. 이 경우는 탐색을 실패한 경우가 된다.
아래 리스트에서 '화' 노드를 탐색해 보자.
| week | data | link | data | link | data | link |
| ➡️ (월 노드의 주소) | 월 | ➡️ (화 노드의 주소) | 화 | ➡️ (수 노드의 주소) | 수 | NULL |
temp에 리스트 헤더가 가리키던 노드(첫 번째 노드)를 임시로 할당한다.
| data | link |
| 월 | ➡️ (화 노드의 주소) |
while 문을 통해 매개변수로 받은 값 '화'를 계속 검사한다.
(이 경우에는 '화' 노드에 걸리게 된다.)
| week | data | link | data | link | data | link |
| ➡️ (월 노드의 주소) | 월 | ➡️ (화 노드의 주소) | 화 | ➡️ (수 노드의 ) | 수 | NULL |
'화' 노드를 리턴하게 된다.
🎯 3. 원형 연결 리스트
📌 3 - 1. 원형 연결 리스트의 개념
원형 연결 리스트는 우리가 이전까지 봤던 연결리스트와 비슷하다.
그러나 이름에서도 볼 수 있듯이 연결 구조가 원형 구조로 이루어지게 된다.
즉, 마지막 노드의 link가 NULL이 아닌, 첫 번째 원소를 가리키게 된다.
아래는 그 예시이다.

📌 3 - 2. 원형 연결 리스트의 알고리즘
📌 3 - 3. 원형 연결 리스트의 프로그램
원형 연결 리스트에서는 첫 번째 노드로 삽입, 중간에 노드 삽입, 노드 삭제 알고리즘을 살펴볼 예정인데,
본 글에서는 C 언어를 작성하지 않을 예정이라 알고리즘과 프로그램을 통합해서 진행하겠다. (사실 이전 장에서도 그렇게 진행했다.😅)
리스트에 첫 번째 노드로 삽입하는 알고리즘
이번 알고리즘에도 이전에 보던 것과 같이 리스트가 비어있는지 검사하고, 그 결과에 따른 알고리즘을 진행한다.
- 새 노드 생성
- 새 노드에 데이터 할당
- if(리스트가 비어있는가?)
- true일 경우
- 리스트 헤더에 삽입할 새 노드의 주소를 할당하고
- 새 노드의 link에 자기 자신의 주소를 할당한다 (원형)
- false일 경우
- temp에 리스트 헤더가 가리키는 노드(첫 번째 노드)를 임시로 할당하고
- while(temp.link가 리스트 헤더가 가리키는 값과 같지 않을 때 까지)
- temp에 temp.link(다음 노드)를 할당한다.
- while문이 끝나면 temp는 리스트의 마지막 노드가 되고, 새 노드의 링크에 temp가 가리키던 링크를 할당한다
- temp의 link에 삽입할 새 노드의 주소 값을 할당한다.
- 리스트 헤더에 삽입할 새 노드의 주소 값을 할당한다.
- true일 경우
리스트가 비어있지 않다고 가정하고, 아래 리스트에 '월' 노드를 삽입하는 과정을 살펴보자.
| week | data | link | data | link |
| ➡️ (화 노드의 주소) | 화 | ➡️ (수 노드의 주소) | 수 | ➡️ (화 노드의 주소) |
삽입할 새 노드를 생성한다.
| data | link |
새 노드에 데이터를 할당한다,
| data | link |
| 월 |
if(리스트가 비어있는가?)를 통과한 뒤
temp에 리스트 헤더가 가리키던 노드를 임시로 저장한다.
| data | link |
| 화 | ➡️ (수 노드의 주소) |
while(temp의 link가 리스트 헤더가 가리키는 노드와 같은가?)문을 돌려서 temp가 마지막 값이 되도록 한다.
| data | link |
| 수 | ➡️ (화 노드의 주소) |
새 노드의 link에 temp의 link 값을 할당한다.
| data | link |
| 월 | ➡️ (화 노드의 주소) |
temp의 링크에 새 노드의 주소를 할당한다.
| data | link | data | link | data | link |
| 월 | ➡️ (화 노드의 주소) | 화 | ➡️ (수 노드의 주소) | 수 | ➡️ (월 노드의 주소) |
리스트 헤더에 새 노드의 주소를 할당한다.
| week | data | link | data | link | data | link |
| ➡️ (월 노드의 주소) | 월 | ➡️ (화 노드의 주소) | 화 | ➡️ (수 노드의 주소) | 수 | ➡️ (월 노드의 주소) |
리스트 중간에 노드를 삽입하는 알고리즘
이번 알고리즘은 삽입할 노드의 이전 노드를 매개변수로 받고, 중간에 리스트가 비어있는지 확인하고 그에 따른 동작을 수행한다.
- 삽입할 새 노드 생성
- 새 노드에 데이터 할당
- if(리스트가 비어있는가?)
- true일 경우
- 리스트 헤더에 새 노드의 주소를 할당하고
- 새 노드의 link에 자기 자신의 주소를 할당한다
- false일 경우
- 새 노드의 link에 이전 노드의 link를 할당한다.
- 이전 노드의 link에 새 노드의 주소를 할당한다.
- true일 경우
단순 연결 리스트의 리스트 중간 삽입 과정과 비슷해서 넘어가겠다.
원형 연결 리스트의 마지막으로 노드를 삽입하는 과정이 없는 이유는 원형 연결 리스트에는 마지막이 없기 때문이다.
원형으로 계속 연결되기 때문에 처음과 중간만 존재한다.
노드를 삭제하는 알고리즘
해당 알고리즘을 수행하기 위해서는 삭제할 노드의 이전 노드를 알고 있어야 한다.
이번에 살펴 볼 알고리즘에서는 삭제할 노드가 존재하는지에 대한 if가 없으므로 따로 추가해 보면 더 좋은 알고리즘이 될 것이다.
- if(리스트가 비어있는가?)
- true일 경우
- 에러메시지를 출력한다.
- false일 경우
- old의 이전 노드의 link(삭제할 노드)를 임시로 저장한다.
- 삭제할 노드 이전 노드의 link에 삭제할 노드(old)의 link를 할당한다.
- if(삭제할 노드가 리스트의 첫 번째 노드인가?)
- true일 경우
- 리스트 헤더에 삭제할 노드의 link를 할당한다.
- true일 경우
- 삭제할 노드의 메모리 공간 점유를 해제한다.
- true일 경우
아래 리스트에서 '월' 노드를 삭제해보자.
| week | data | link | data | link | data | link |
| ➡️ (월 노드의 주소) | 월 | ➡️ (화 노드의 주소) | 화 | ➡️ (수 노드의 주소) | 수 | ➡️(월 노드의 주소) |
if문을 통과해서 리스트에 노드가 있다는 것을 확인한 뒤,
old에 삭제할 노드 이전 노드의 link(삭제할 노드)를 임시로 할당한다.
| data | link |
| 월 | ➡️ (화 노드의 주소) |
삭제할 노드 이전 노드의 link에 삭제할 노드의 link를 할당한다.
| week | data | link | data | link | data | link |
| ➡️ (월 노드의 주소 ) | 월 | ➡️ (화 노드의 주소) | 화 | ➡️ (수 노드의 주소) | 수 | ➡️ (화 노드의 주소) |
if(삭제할 노드가 리스트의 첫 번째 노드인가?)
첫 번째 노드이니, 리스트 헤더가 가리키는 주소를 삭제할 노드의 link로 변경한다.
| week | data | link | data | link |
| ➡️ (화 노드의 주소) | 화 | ➡️ (수 노드의 주소) | 수 | ➡️ (화 노드의 주소) |
삭제할 노드의 메모리 공간 점유를 해제한다.
🎯 4. 이중 연결 리스트
📌 4 - 1. 이중 연결 리스트의 개념
단순 연결리스트는 선행 노드로 접근하기 어렵다는 점을 개선하여 원형 연결 리스트를 구성했지만, 원형 연결 리스트 역시 이전 노드로 접근하려면 전체 리스트를 한 바퀴 순회해야 하는 문제가 있다.
따라서 이번에 살펴볼 연결 리스트는 그러한 문제를 해결한 이중 연결 리스트이다.
이중 연결 리스트의 한 노드는 2개의 link를 포함하며 다음과 같이 이전 노드를 가리키는 llink와 다음 노드를 가리키는 rlink가 있다.
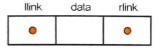
이 노드가 연결되면 다음과 같이 연결된다.

이중 연결 리스트에서는 다음 관계가 성립한다
p = p.llink.rlink = p.rlink.llink
노드 = 노드의 이전 노드의 다음 노드 = 노드의 다음 노드의 이전 노드
📌 4 - 2. 이중 연결 리스트의 알고리즘
📌 4 - 3. 이중 연결 리스트의 프로그램
이번에도 원형 연결 리스트와 같은 이유로 알고리즘과 프로그램을 통합하여 살펴본다.
이번에는 노드를 삽입하는 알고리즘과 삭제하는 알고리즘을 살펴보자.
이중 연결 리스트에 노드를 삽입하는 알고리즘
이번 알고리즘을 수행하기 위해서는 삽입할 노드의 이전 노드를 알고 있어야 한다.
알고리즘의 순서는 다음과 같다.
- 삽입할 새 노드를 생성한다.
- 새 노드에 데이터를 할당한다.
- 새 노드의 rlink에 이전 노드의 rlink를 할당한다.
- 이전 노드의 rlink에 새 노드의 주소를 할당한다.
- 새 노드의 llink에 이전 노드의 주소를 할당한다.
- 새 노드의 다음 노드의 llink에 새 노드의 주소를 할당한다.
다음 이중 연결 리스트에서 '화' 노드를 삽입해 보자.
| week | llink | data | rlink | llink | data | rlink |
| ➡️ (월 노드의 주소) | NULL | 월 | ➡️ (수 노드의 주소) | ⬅️ (월 노드의 주소) | 수 | NULL |
삽입할 새 노드를 생성한다.
| llink | data | rlink |
새 노드에 데이터를 할당한다.
| llink | data | rlink |
| 화 |
새 노드의 rlink에 이전 노드의 rlink를 할당한다.
| llink | data | rlink |
| 화 | ➡️ (수 노드의 주소) |
이전 노드의 rlink에 새 노드의 주소를 할당한다.
| week | llink | data | rlink | llink | data | rlink | llink | data | rlink |
| ➡️ (월 노드의 주소) | NULL | 월 | ➡️ (화 노드의 주소) | 화 | ➡️ (수 노드의 주소) | ⬅️ (월 노드의 주소) | 수 | NULL |
새 노드의 llink에 이전 노드의 주소를 할당한다.
| week | llink | data | rlink | llink | data | rlink | llink | data | rlink |
| ➡️ (월 노드의 주소) | NULL | 월 | ➡️ (화 노드의 주소) | ⬅️ (월 노드의 주소) | 화 | ➡️ (수 노드의 주소) | ⬅️ (월 노드의 주소) | 수 | NULL |
새 노드의 다음 링크의 llink에 새 노드의 주소를 할당한다.
| week | llink | data | rlink | llink | data | rlink | llink | data | rllink |
| ➡️ (월 노드의 주소) | NULL | 월 | ➡️ (화 노드의 주소) | ⬅️ (월 노드의 주소) | 화 | ➡️ (수 노드의 주소) | ⬅️ (화 노드의 주소) | 수 | NULL |
이중 연결 리스트에 노드를 삭제하는 알고리즘
이 알고리즘을 수행하기 위해서는 삭제할 노드만 알고 있으면 알고리즘을 수행할 수 있다.
순서는 다음과 같다.
- 삭제할 노드의 이전 노드의 rlink (old.llink.rlink)의 값을 삭제할 노드의 rlink 값으로 할당한다.
- 삭제할 노드의 다음 노드의 llink (old.rlink.llink)의 값을 삭제할 노드의 llink 값으로 할당한다.
- 삭제할 노드의 메모리 공간 점유를 해제한다.
아래 이중 연결 리스트에서 '화' 노드를 삭제해 보자.
| week | llink | data | rlink | llink | data | rlink | llink | data | rlink |
| ➡️ (월 노드의 주소) | NULL | 월 | ➡️ (화 노드의 주소) | ⬅️ (월 노드의 주소) | 화 | ➡️ (수 노드의 주소) | ⬅️ (화 노드의 주소) | 수 | NULL |
삭제할 노드의 이전 노드의 rlink의 값을 삭제할 노드의 rlink 값으로 할당한다.
| week | llink | data | rlink | llink | data | rlink | llink | data | rlink |
| ➡️ (월 노드의 주소) | NULL | 월 | ➡️ (수 노드의 주소) | ⬅️ (월 노드의 주소) | 화 | ➡️ (수 노드의 주소) | ⬅️ (화 노드의 주소) | 수 | NULL |
삭제할 노드의 다음 노드의 llink의 값을 삭제할 노드의 llink 값으로 할당한다.
(이 연산을 수행한 순간 연결 리스트 순서 상에서 삭제할 노드는 없어진다.)
| week | llink | data | rlink | llink | data | rlink |
| ➡️ (월 노드의 주소) | NULL | 월 | ➡️ (수 노드의 주소) | ⬅️ (월 노드의 주소) | 수 | NULL |
마지막으로 삭제할 노드의 메모리 공간 점유를 해제한다.
🎯 5. 연결 리스트의 응용 및 구현
📌 5 - 1. 단순 연결 리스트를 이용한 다항식 표현
3장 선형 리스트에서 선형 리스트로 다항식을 표현했었다.
이번에는 연결 리스트로 다항식을 표현해 보자.
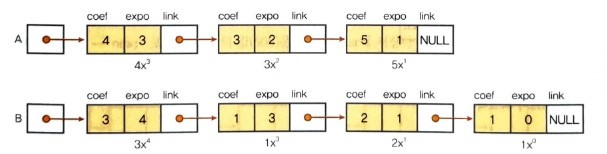
연결 리스트로 다항식을 표현하기 위해서는 다음과 같이 계수와 지수를 저장하기 위한 2개의 데이터 필드가 필요하다.

위의 노드들을 연결하면
4x³ + 3x² + 5x와
3x⁴ + x³ + 2x + 1을 다음과 같이 표현할 수 있다.
📌 5 - 2. 다항식 연결 자료구조의 항 삽입 알고리즘
연결 리스트 다항식의 삽입 알고리즘은 다음과 같다.

📌 5 - 3. 다항식끼리의 덧셈 연산과 알고리즘
📌 5 - 4. 연결 리스트를 이용한 다항식 프로그램
연결 리스트 다항식의 덧셈 연산 알고리즘은 다음과 같다.

'Computer Science > 자료구조' 카테고리의 다른 글
| [자료구조] - 스택 (1) | 2023.10.29 |
|---|---|
| [자료구조] - 순차 자료구조와 선형 리스트 (1) | 2023.09.23 |
| [자료구조] - 자료구조 구현을 위한 C 프로그래밍 기법 (0) | 2023.09.23 |
| [자료구조] - 자료구조 소개 (0) | 2023.09.10 |



