
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 후위표기법변환
- 제어유니트
- 깃허브 로그인
- 연결자료구조
- 자료구조
- 모던 자바스크립트 Deep Dive
- 컴퓨터 구조론
- 리액트
- pug
- 자바스크립트 배열
- 유튜브 클론코딩
- Express
- Nodemon
- react
- 제어유닛
- 보조저장장치
- 후위표기법연산
- MongoDB
- mongoose
- 자바스크립트
- 유튜브클론코딩
- 컴퓨터 구조
- CPU
- Session
- 프론트엔드
- node.js
- 마이크로명령어
- 표현식과 문
- cookie
- JavaScript
- Today
- Total
909 Devlog
[컴퓨터 구조] - 기억장치 본문
👋 본 글은 "컴퓨터 구조론" 책을 읽고 요약, 정리한 글입니다.

책 구매 링크에서 책을 확인하실 수 있습니다.
5장에서는 다양한 종류의 기억장치들을 분석함으로써 계층적 기억장치 시스템의 개념을 이해하도록 한다. 그런 다음에 반도체 기억장치의 내부 조직을 살펴보고, 그들을 이용하여 기억장치 모듈을 설계하는 방법에 대하여 설명한다. 또한 기억장치 대역폭 향상을 위한 기술인 DDR SDRAM과 기억장치 랭크의 원리와 구성 방법에 대해서도 분석한다. 그리고 주기억장치의 속도를 본완하기 위한 캐시 메모리의 구조와 설계 원리에 대하여 공부한 다음에, 차세대 반도체 기억장치 유형인 PRAM, FRAM 및 MRAM의 원리에 대해서도 간략히 살펴본다.
🎯 1. 기억장치의 분류와 특성
기억장치 액세스(memory access)란? : CPU가 어떤 정보를 기억장치에 쓰거나 기억장치로부터 읽는 동작
기억장치의 액세스 유형
- 순차적 액세스(sequential access) : 저장된 정보를 처음부터 순서대로 액세스 하는 방식 [예 : 자기 테이프]
- 직접 액세스(direct access) : 액세스할 위치 근처로 직접 이동한 다음에 순차적 검색을 통하여 최종 위치에 도달하는 방식 [예 : 디스크, CD-ROM]
- 임의 액세스(random access) : 주소에 의해 직접 기억 장소를 찾아 액세스 하며, 어떤 기억 장소든 액세스 하는 시간이 동일 [예 : 반도체 기억장치]
- 연관 액세스(associative access) : 저장된 내용의 특정 비트들을 비교하여 일치하는 내용을 액세스 [예 : 연관 기억장치]
기억장치 시스템을 설계하는 데 있어서 고려해야 할 주요 특성들
- 용량(capacity)
- 액세스 속도
전송 단위(unit of transfer)
- CPU가 한 번의 기억장치 액세스에 의하여 읽거나 쓸 수 있는 비트 수
- 주기억장치 : 단어(word) 단위
- 보조저장장치 : 블록(512 바이트 혹은 1K 바이트) 단위
주소지정 단위
- 주소가 지정된 각 기억 장소 당 저장되는 데이터 길이
- 바이트 단위 혹은 단어 단위
- 주소 비트 수 n와 주소지정 단위 수 N과의 관계 : 2ⁿ = N
액세스 시간 : 주소와 쓰기 / 읽기 신호가 도착한 순간부터 데이터 액세스가 완료되는 순간까지의 시간
아래는 1장에서 봤던 쓰기 및 읽기 시간 흐름도이다
데이터 전송률 : 기억장치로부터 초당 액세스되는 비트 수(bps) = (1 / 액세스 시간) X (한 번에 읽히는 데이터 비트 수)
[예 : 액세스 시간 = 100ns, 액세스 단위 = 32비트인 경우
데이터 전송률 = (1 / 100ns) X 32/8 = 40[MBytes/sec](MBps) = 320[Mbits/sec](Mbps)]
기억장치의 유형
- 기억장치의 제조 재료에 따른 유형
- 반도체 기억장치 : 반도체 물질인 실리콘 칩을 이용한 기억장치 [예 : RAM, ROM, 플래시 메모리]
- 자기-표면 기억장치 : 자화 물질로 코팅된 표면에 정보를 저장하는 기억장치 [예 : 디스크]
- 광 저장장치 : 레이저 광을 이용하여 저장하는 기억장치 [예 : CO-ROM, DVD]
- 데이터를 저장하는 성질에 따른 유형
- 휘발성 기억장치 : 전원 공급이 중단되면 내용이 지워지는 기억장치 [예 : RAM]
- 비휘발성 기억장치 : 전원 공급에 관계없는 영구 저장장치 [예 : ROM, 디스크, CD-ROM]
- 삭제불가능 기억장치
- 내용 변경이 불가능한 기억장치 [예 : ROM]
🎯 2. 계층적 기억장치시스템
📌 2 - 1. 필요성과 효과
필요성 : 기억장치들은 속도, 용량 및 가격 측면에서 매우 다양하며, 적절한 성능(속도), 용량 및 가격의 기억장치 구성 필요
효과 : 기억장치시스템의 성능 대 가격비(performance / cost ratio) 향상
기억장치 특성들간의 관계
- 액세스 속도가 높아질수록, 비트당 가격은 높아진다
- 용량이 커질수록, 비트당 가격은 낮아진다
- 용량이 커질수록, 액세스 시간을 길어진다
계층적 기억장치시스템의 기본 구성 방법
- 첫 번째 계층 기억장치 : 속도가 빠른(가격은 높은, 용량은 적은)
- 두 번째 계층 기억장치 : 속도는 느린(가격은 낮은, 용량은 많은)
2-단계 계층적 기억장치
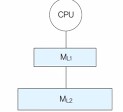
동작 원리 : 원하는 데이터가 첫 번째 계층 기억장치에 있다면 즉시 액세스하고, 만약 없다면, 두 번째 계층의 기억장치를 액세스
[예 : 첫 번째 계층 기억장치의 액세스 시간 = 10ns
두 번째 계층 기억장치의 액세스 시간 = 100ns
액세스할 정보다 첫 번째 계층 기억장치에 있을 확률 = 50%
➡️ 평균 기억장치 액세스 시간 = (0.5 X 10ns) + (0.5 X 100ns) = 55ns]
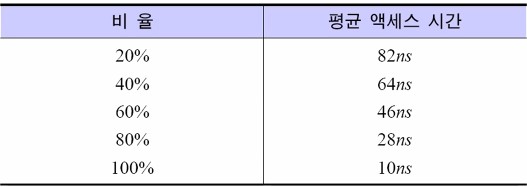
아래는 데이터가 첫 번째 계층의 기억장치에 있는 비율에 따른 평균 액세스 시간을 보여주는 그림이다.
지역성의 원리(principle of locality)
- 기억장치의 액세스가 몇몇 특정 영역에 집중되는 현상
- 짧은 시간을 기준으로 보면, 프로세서가 기억장치의 한정된 몇몇 위치들을 집중적으로 액세스하면서 작업을 수행
- 프로그램이 실행되는 동안에 일반적으로 지역성의 원리에 의해, 첫 번째 계층의 기억장치에 대한 액세스 횟수가 두 번째 계층의 기억장치에 대한 액세스보다 훨씬 더 많음
따라서 지역성의 원리가 적용되는 경우, 평균 기억장치 액세스 시간이 단축됨
📌 2 - 2. 기억장치 계층
아래는 기억장치 계층을 나타내는 그림이다.
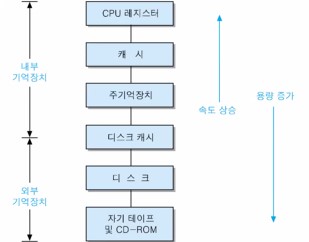
- 상위 층으로 갈수록
- 비트당 가격이 높아지고, 용량은 감소
- 액세스 시간은 짧아지고, CPU에 의한 액세스 빈도는 상승
- 하위 계층으로 내려갈수록
- 비트당 가격은 떨어지며,
- 용량이 더 커지고,
- 지역성의 원리로 인하여 액세스 빈도는 더 낮아진다.
- 캐시 기억장치
- 주기억장치의 액세스 속도가 CPU에 비하여 현저히 느리기 때문에 주기억장치로부터 데이터를 읽어오는 동안에 CPU가 오랫동안 기다려야 하므로, 그에 따른 성능 저하를 줄이기 위하여 CPU와 주기억장치 사이에 설치하는 고속의 반도체 기억장치
- 디스크 캐시
- 디스크(보조저장장치)와 주기억장치의 액세스 속도 차이를 줄이기 위하여 그 사이에 설치하는 반도체 기억장치
- 주기억장치로부터 디스크로 잃혀나갈 정보들을 일시적으로 저장하는 버퍼 역할
- 위치 : 주기억장치, I / O 프로세서 보드, 혹은 제어기 보드
🎯 3.반도체 기억장치
📌 3 - 1. RAM
특성
- 임의 액세스 방식
- 반도체 집적회로 기억장치(semiconductor IC memory)
- 데이터 읽기와 쓰기 모두 가능(RWM : Read-Writable M)
- 휘발성(volatile) : 전원 공급이 중단되면 내용이 지워짐
제조 기술에 따른 분류
- DRAM (Dynamic RAM)
- 캐패시터에 전하를 충전하는 방식으로 데이터를 저장하는 기억 소자들로 구성 ➡️ 집적 밀도가 높다
- 데이터의 저장 상태를 유지하기 위하여 주기적인 재충전 필요
- 집적 밀도가 더 높으며, 같은 용량의 SRAM 보다 가격이 더 저렴
- 용량이 큰 주기억장치로 사용
- SRAM (Static RAM)
- 기억 소자로서 플립-플롭을 이용 ➡️ 집적 밀도가 낮다
- 전력이 공급되는 동안에는 재충전 없이도 데이터 계속 유지 가능
- DRAM 보다 다소 더 빠르다
- 높은 속도가 필요한 캐시 기억장치로 사용
아래는 1K x 8 RAM 칩의 블록선도이고 (1K는 주소 버스에 사용, 8은 데이터 버스에 사용한 모습, 제어 버스 3비트 총 10 + 8 + 3 = 21비트로 구성된 시스템 버스가 필요)
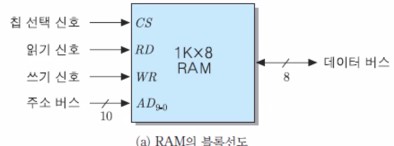
아래는 제어 신호들에 따른 그 RAM의 동작들이다.
(CS : Chip Select, RD : ReaD, WR : WRite)
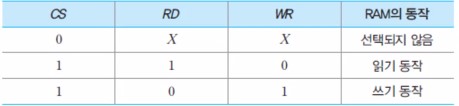
64-비트 RAM의 내부 조직 예 1 : 8 x 8 (64) 비트 조직
8비트씩 저장하는 8개의 기억 장소들로 구성
주소 비트 수 = 3, 데이터 입출력 선의 수 = 8
아래는 8 x 8비트 조직 및 주소지정을 나타내는 그림이다.
용량에 따른 주소 비트 수
- [예] 8Kbit RAM
- 1K x 8비트 조직인 경우, 주소 = 10비트 필요
- [예] 1Mbit RAM
- 128K x 8비트 조직인 경우, 주소 = 17비트 필요
- [예] 1Gbit RAM
- 128M x 8비트 조직인 경우, 주소 = 27비트 필요
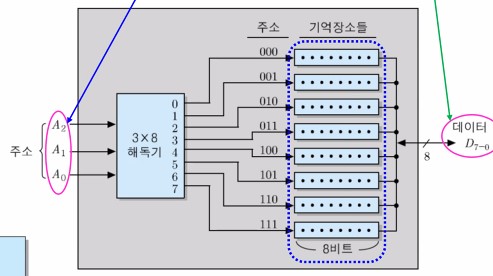
64-bit RAM의 내부 조직 예2 : 16 x 4 조직
4비트씩 저장하는 16개의 기억 장소들로 구성
주소 비트 수 = 4, 데이터 입출력 선의 수 = 4
아래는 16 x 4비트 조직 및 주소지정을 나타내는 그림이다.
용량에 따른 주소 비트 수
- [예] 8Kbit RAM
- 2K x 4비트 조직인 경우, 주소 = 11비트 필요
- [예] 1Mbit RAM
- 256K x 4비트 조직인 경우, 주소 = 18비트 필요
- [예] 1Gbit RAM
- 256M x 4비트 조직인 경우, 주소 = 28비트 필요
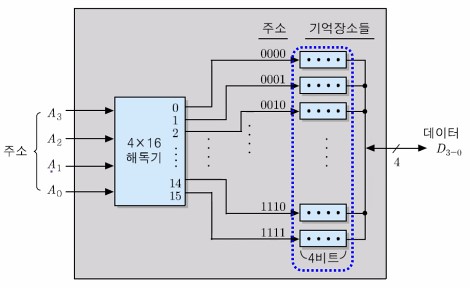
64-bit RAM의 내부 조직 예3 : 64 x 1조직
1비트씩 저장하는 64개의 기억 장소들로 구성
6개의 주소 비트들이 필요 (2⁶ = 64)
- 상위 3 비트들은 8개의 행들 중에서 한 개를 선택하고,
- 하위 3 비트들은 8개의 열들 중에서 한 개를 선택
두 개의 3 x 8 해독기 필요
데이터 입출력 선의 수 = 1
아래는 64 x 1비트 조직 및 주소지정을 나타내는 그림이다.
용량에 따른 주소 비트 수
- [예] 8Kbit RAM
- 8K x 1비트 조직인 경우, 주소 = 13비트 필요
- [예] 1Mbit RAM
- 1M x 1비트 조직인 경우, 주소 = 20비트 필요
- [예] 1Gbit RAM
- 1G x 1비트 조직인 경우, 주소 = 30비트 필요\
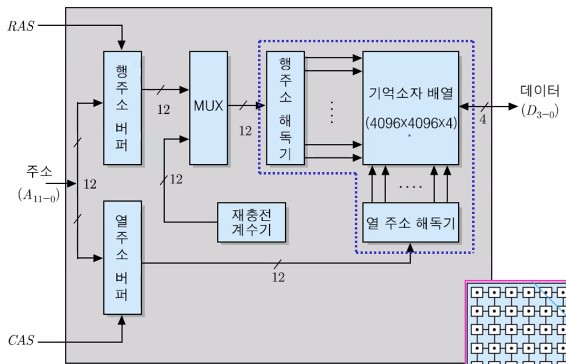
RAM 내부 조직의 예 4 : 16M x 4 조직 (64Mbit)
기억소자 : 4,096(4K) x 4,096(4K) x 4비트 배열
- 4,096개의 행과 4.096개의 열들로 이루어진 정방형 구조
- 각 기억 장소에는 4개의 데이터 비트들을 저장
기억 장소의 수 = 16M개
➡️ 전체 24비트의 주소 선들이 필요
(RAS(Row Address Strobe) 신호와 CAS(Column Address Strobe) 신호를 이용하여, 칩으로 실제 입력되는 주소 선들의 수는 12개(24개의 반)만 되도록 함)
아래는 16M x 4비트 (64Mbit) RAM의 내부 조직을 나타내는 그림이다.
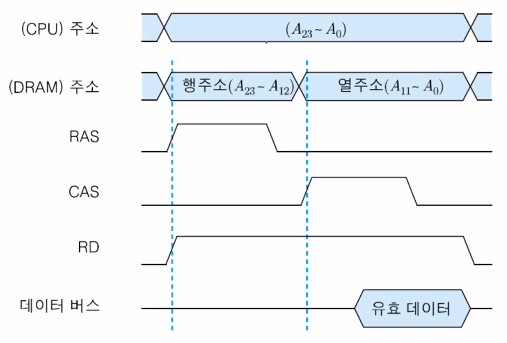
아래는 DRAM 읽기 동작의 타이밍도를 나타내는 그림이다.
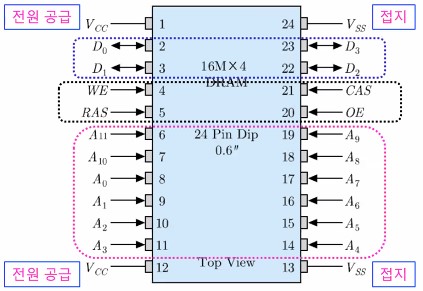
아래는 64Mbit DRAM 패키지의 입출력 핀 구성을 나타내는 그림이다.
📌 3 - 2. ROM
- 영구 저장이 가능한 반도체 기억장치
- 읽는 것만 가능하고, 쓰는 것은 불가능
- 아래 내용들의 저장에 사용
- 시스템 초기화 및 진단 프로그램 [예 : PC의 BIOS 프로그램]
- 빈번히 사용되는 함수들을 위한 서브루틴들
- 제어 유니트의 마이크로프로그램
아래는 64KByte ROM의 블록선도를 나타내는 그림이다.
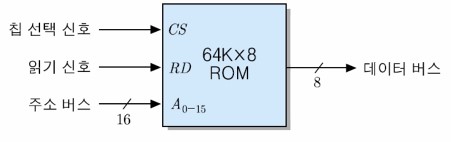
ROM의 종류
- PROM : 사용자가 한 번은 쓰는 것이 가능한 ROM
- EPROM : 자외선을 이용하여 내용을 지우는 것이 가능한 PROM. 여러 번쓰기가 가능(수십, 수백 번)
- EEPROM : 전기적으로 지울 수 있는 EPROM. 데이터 갱신 횟수 제한(수만 번 정도)
플래시 메모리
- NAND형 : 페이지(2KB / 4KB) 단위 읽기 / 쓰기 가능, 블록(64 / 128 페이지) 단위 삭제, [비교 : NOR형은 바이트 단위 읽기 / 쓰기 가능]
- EEPROM에 비하여 삭제 시간이 더 빠르고, 집적 밀도도 더 높음
- 삭제 횟수 제한 (100,000 ~ 1,000,000회)
- 하드 디스크를 대체하는 SSD(solid state drive)의 구성요소
🎯 4. 기억장치 모듈의 설계
- 기억장치 칩의 데이터 I / O 비트 수가 단어 길이보다 적은 경우 ➡️ 여러 개의 칩들을 병렬 접속하여 기억장치 모듈을 구성
- 단어의 길이 N 비트, 기억장치 칩의 데이터 I / O 비트 수 = B라면, ➡️ N / B개의 칩들을 병렬접속
- [예] N = 8일 때, 16 x 4비트 RAM 칩들을 이용한 기억장치 모듈의 설계
- 방법 : 2개의 RAM 칩들을 병렬 접속
- 모듈의 용량 : (16 x 4) x 2개 = 16 x 8비트 = 16단어
- 주소 비트(4개 : A₀ ~ A₃) : 두 칩들에 공통으로 접속
- 칩 선택 신호(CS)를 두 칩들에 공통으로 접속
- 주소 영역 : 0000 ~ 1111
- 아래 그림은 두 개의 RAM 칩들을 병렬접속한 예를 나타내는 그림이다.
- [예] 1K x 8비트 RAM 칩들을 이용한 1k x 32비트 기억장치 모듈의 설계
- 방법 : 4개의 RAM 칩들을 병렬 접속
- 모듈의 용량 : (1K x 8) x 4개 = 1K x 32비트 = 1Kword
- 주소비트(10개: A0 ~ A9) : 모든 칩들에 공통으로 접속
- 주소 영역 : 000H ~ 3FFH (단, H는 16진수 표기법을 나타내는 표시) (3FF = 11 1111 1111)
- 데이터 저장 : 동일한 기억장치 주소에 대하여 칩 당 (32비트들 중의) 8 비트씩 분산 저장
아래 그림은 1K x 32비트 기억장치 모듈을 나타내는 그림이다.
2. 필요한 기억장소보다 기억장치 칩의 기억장소 수가 적은 경우 ➡️ 여러 개의 칩들을 직렬 접속하여 모듈을 구성
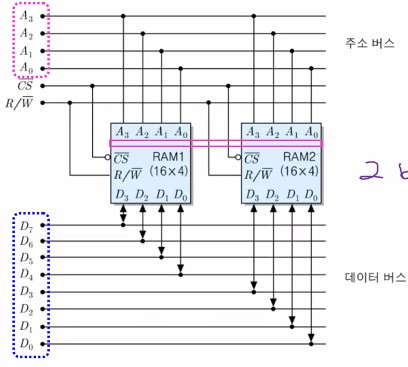
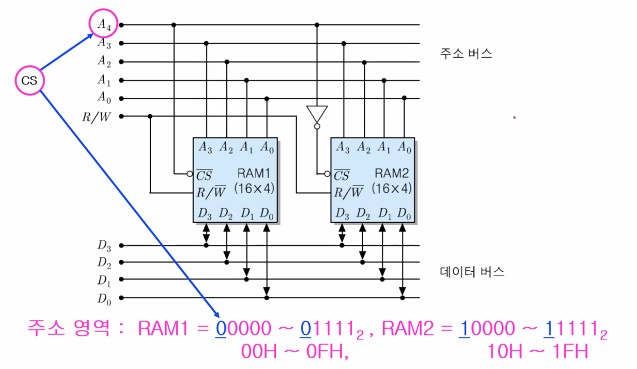
- [예] 두 개의 16 x 4비트 RAM 칩들을 이용한 32 x 4비트 기억장치 모듈의 설계
- 방법 : 2개의 RAM 칩들을 직렬 접속
- 모듈의 용량 : 2개 x (16 x 4) = 32 x 4비트
- 주소 비트 수 : 5개 (A4 ~ A0)
- A4 : 칩 선택 신호(CS)로 사용
- A3 ~ A0 : 두 칩들에 공통으로 접속
- 주소 영역 (기억장치를 반으로 나누어서)
- RAM1 : 00000 ~ 01111, RMA2 : 10000 ~ 11111
아래는 두 개의 RAM 칩들을 직렬 접속한 예 (16 x 4비트 RAM 칩들을 이용한 32 x 4비트 기억장치 모듈)을 나타내는 그림이다.
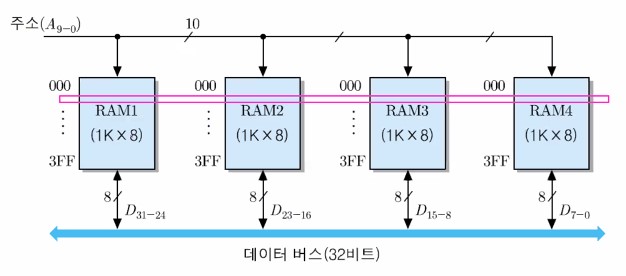
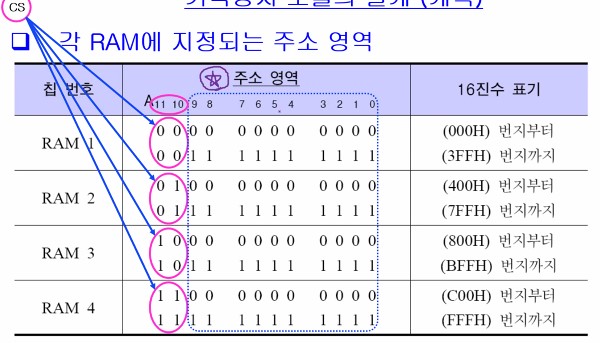
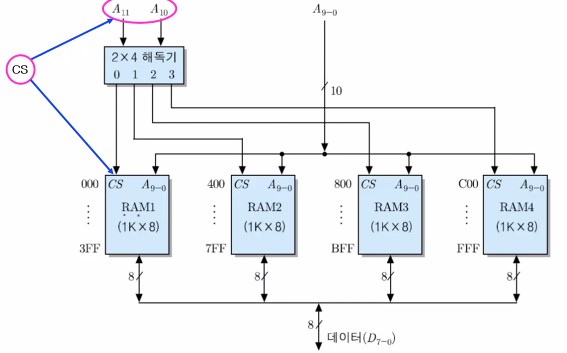
- [예] 1K x 8비트 RAM 칩들을 이용한 4K x 8비트 기억장치 모듈
- 방법 : 4개의 RAM 칩들을 직렬 접속
- 모듈의 용량 : (1K x 8) x 4개 = 4K x 8비트 = 4KByte
- 주소 비트 (12개 : A11 ~ A0) 접속 방법
- 하위 10비트 (A9 ~ A0) : 모든 칩들에 공통으로 접속
- 상위 2비트 (A11, A10) : 주소 해독기를 이용하여 4개의 칩 선택 신호(CS) 발생
- 전체 주소 영역 : 000H ~ FFFH
- 데이터 버스 : 모든 기억장치 칩에 공통 접속 (한 번에 8비트씩 액세스)
아래는 위 예시에서의 주소 영역을 나타내는 그림이다.
아래는 1K x 8비트 RAM을 이용한 4K x 8비트 기억장치 모듈의 구성을 나타내는 그림이다. (직렬)
기억장치 모듈의 설계 순서
- 컴퓨터시스템에 필요한 기억장치 용량 결정
- 사용할 칩들을 결정
- 주소 표를 작성
- 세부 회로 설계
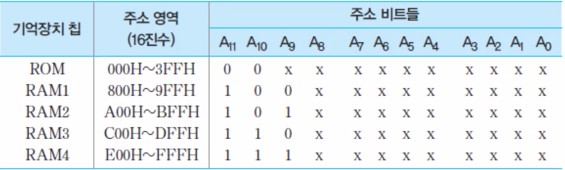
[예] 8-비트 마이크로컴퓨터를 위한 기억장치의 설계
- 용량 : 1KByte ROM, 2KByte RAM
- 사용 가능한 칩들 : 1K x 8비트 ROM 1개, 512 x 8비트 RAM 4개
- 주소 영역 : ROM = 0번지부터, RAM = 800H 번지 부터
- 기억장치 주소 표는 아래와 같다.
아래는 8-비트 마이크로컴퓨터를 위한 기억장치 설계의 예를 나타내는 그림이다.
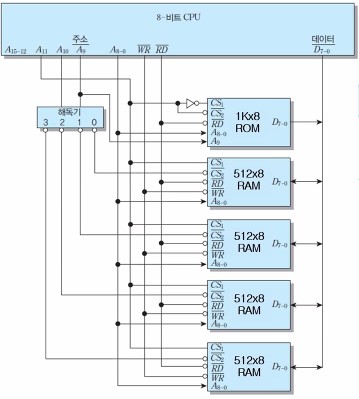
CPU로부터 나오는 선들은 시스템 버스를 나타내며 각각 주소 버스, 제어 버스(WR, RD), 데이터 버스(데이터)를 의미한다.
🎯 5. 캐시 메모리
사용 목적 : CPU와 주기억장치의 속도 차이로 인한 CPU 대기 시간을 최소화 시키기 위하여 CPU와 주기억장치 사이에 설치하는 고속 반도체 기억장치
특징
- 주기억장치보다 액세스 속도가 빠른 칩 사용
- 가격 및 제한된 공간 때문에 용량이 적다
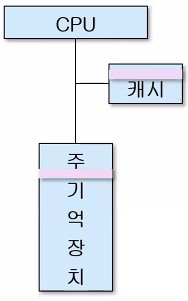
용어
- 캐시 적중 : CPU가 원하는 데이터가 캐시에 있는 상태
- 캐시 미스 : CPU가 원하는 데이터가 캐시에 없는 상태, 이 경우에는 주기억장치로부터 데이터를 읽어온다.
- 적중률 : 캐시에 적중되는 정도 (H) H = 캐시에 적중되는 횟수 / 전체 기억장치 액세스 횟수
- 캐시의 미스율 = 1 - H
- 평균 기억장치 액세스 시간 (Ta) : Ta = H x Tc + (1 - H) x Tm (Tc : 캐시 액세스 시간, Tm : 주기억장치 액세스 시간)
캐시의 적중률이 높아질수록 평군 기억장치 액세스 시간은 캐시 액세스 시간에 접근,
캐시 적중률은 프로그램과 데이터의 지역성에 따라 달라짐
지역성
- 시간적 지역성
- 최근에 액세스된 프로그램이 데이터가 가까운 미래에 다시 액세스 될 가능성이 높다
- 공간적 지역성
- 기억장치 내에 인접하여 저장되어 있는 데이터들이 연속적으로 액세스 될 가능성이 높다
- 순차적 지역성
- 분기가 발생하지 않는 한, 명령어들은 기억장치에 저장된 순서대로 인출되어 실행된다
캐시 설계에 있어서의 공통적인 목표
- 캐시 적중률의 극대화
- 캐시 액세스 시간의 최소화
- 캐시 미스에 따른 지연 시간의 최소화
- 주기억장치와 캐시간의 데이터 일관성 유지 및 그에 따른 오버헤드의 최소화
📌 5 - 1. 캐시 용량
- 용량이 커질수록 적중률이 높아지지만, 비용이 증가
- 주소 해독 및 정보 인출을 위한 주변 회로가 더 복잡
- 액세스 시간이 다소 더 길어짐
📌 5 - 2. 인출 방식
- 요구 인출 방식 : 필요한 정보만 인출해 오는 방법
- 선인출 방식
- 필요한 정보 외에 앞으로 필요할 것으로 예측되는 정보도 미리 인출
- 지역성이 높은 경우에 효과가 높다
주기억장치와 캐시의 조직
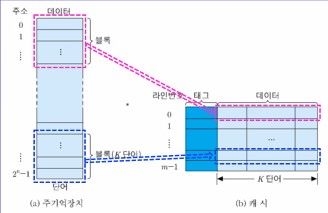
- 블록 : 주기억장치로부터 캐시로 동시에 인출되는 정보 그룹
- 주기억장치 용량 = 2ⁿ 단어,
- 블록 = K 단어 ➡️ 블록의 수 = 2ⁿ/K개
- 라인 : 캐시에서 각 블록이 저장되는 장소
- 태그 : 라인에 적재된 블록을 구분해주는 정보
아래는 주기억장치와 캐시의 조직을 나타내는 그림이다.
📌 5 - 3. 사상 방식
각 주기억장치 블록이 어느 캐시 라인에 적재될 것인지를 결정해 주는 방식으로서, 캐시 내부 조직을 결정
- 직접 사상
- 완전-연관 사상
- 세트-연관사상
주기억장치와 캐시의 주소버스 비트패턴은 동일
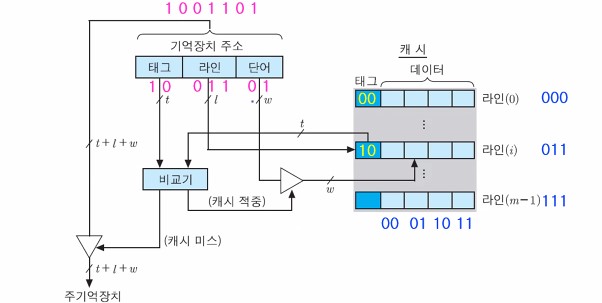
1. 직접 사상
- 주기억장치의 블록들이 지정된 하나의 캐시 라인으로만 적재됨
- 주기억장치 주소 형식은 다음과 같다.

- 태그 필드(t 비트) : 캐시의 라인에 들어가는 블록들 중 하나를 지정
- 라인 필드(l 비트) : 캐시의 m = 2 **(제곱) i개의 라인들 중 하나를 지정
- 단어 필드(w 비트) : 각 블록 내 2 **(제곱) w개 단어들 중 하나를 구분
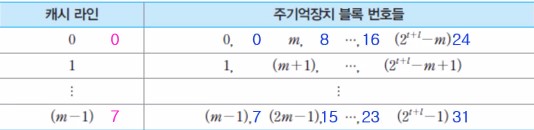
- 주기억장치의 블록 j가 적재될 수 있는 캐시 라인 번호 i : i = j mod(나머지) m (j : 주기억장치 블록 번호, m : 캐시 라인의 전체 수)
라인을 공유하는 주기억장치 블록들
- 각 캐시 라인은 2 ** t개의 블록들에 의하여 공유
- 같은 라인을 공유하는 블록들은 서로 다른 태그를 가짐
아래는 각 캐시 라인을 공유하는 주기억장치 블록들을 나타내는 그림이다.
아래는 직접 사상 캐시의 조직을 나타내는 그림이다.
직접 사상 캐시의 장단점
- 장점
- 하드웨어가 간단하고, 구현 비용이 적게 든다
- 단점
- 각 주기억장치 블록이 적재될 수 있는 캐시 라인이 한 개 뿐이기 때문에, 그 라인을 공유하는 다른 블록이 적재되는 경우에는 swap-out 됨
직접 사상 캐시의 예
- 주기억장치 용량 = 128 바이트, 1단어 = 1바이트
- 주기억장치 주소 = 7비트
- 블록 크기 = 4바이트, 즉, 4단어 (32개의 블록들로 구성)
- 캐시 크기 = 32 바이트
- 캐시 라인 크기 = 4바이트 (블록 크기와 동일)
- 전체 캐시 라인의 수, m = 32 / 4 = 8개
아래는 위의 예를 나타내는 그림이다.
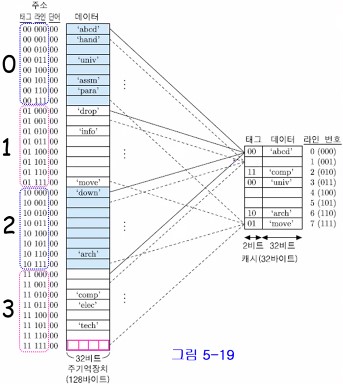
위 예에서
1. 0101000 : 캐시 미스, 2번 라인의 데이터 필드 : 'info', 태그 : 01
2. 0001100 : 캐시 적중, 3번 라인에 적재되어 있음
3. 1110100 : 캐시 미스, 5번 라인의 데이터 필드 : 'tech', 태그 : 11
4. 1011000 : 캐시 적중, 6번 라인에 적재되어 있음
2. 완전-연관 사상
- 주기억장치 블록이 캐시의 어떤 라인으로든 적재 가능
- 태그 필드 = 주기억장치 블록 번호
- 기억장치 주소 형식은 다음과 같다

- 직접 사상의 예에 완전-연관 사상을 적용했을 때는 다음과 같다.

다음은 완전-연관 사상 캐시의 조직을 나타내는 그림이다.
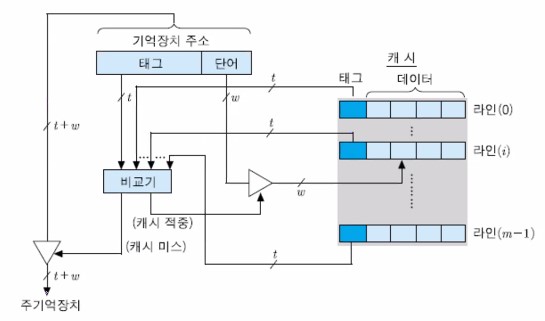
완전-연관 사상 캐시의 장단점
- 장점
- 새로운 블록이 캐시로 적재될 때 라인의 선택이 매우 자유롭다
- 지역성이 높다면, 적중률이 매우 높아진다
- 단점
- 캐시 라인들의 태그들을 병렬로 검사하기 위하여 가격이 높은 연관 기억장치 및 복잡한 주변 회로가 필요
아래는 완전-연관 사상의 예를 나타내는 그림이다.
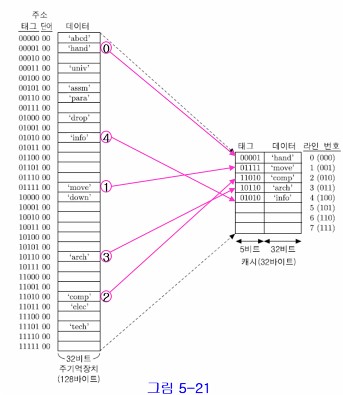
위 예에서
1. 1011000 : 캐시 적중, 현재 3번 라인에 적재되어 있음
2. 0010100 : 캐시 미스, 첫 번째 빈 라인인 5번 라인에 적재된다 (태그 = 00101, 데이터 = 'assm')
3. 0000000 : 캐시 미스, 라인 번호 순으로 6번 라인에 적재된다 (태그 = 00000, 데이터 = 'abcd')
4. 011100 : 캐시 적중, 현재 1번 라인에 적재되어 있음
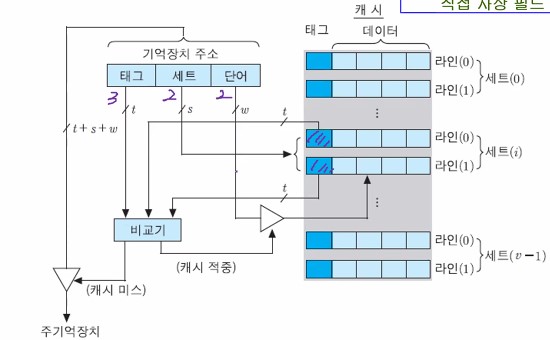
3. 세트-연관 사상
- 직접 사상과 완전-연관 사상의 조합
- 주기억장치 블록 그룹이 하나의 캐시 세트를 공유하며, 그 세트에는 두 개 이상의 라인들이 적재될 수 있음
- 캐시는 v개의 세트들로 나누어지며, 각 세트들은 k개의 라인들로 구성 (k-way 세트-연관 사상이라고 부름)
- 주기억장치 블록이 적재될 수 있는 캐시 세트의 번호 i : i = mod v (i : 캐시 세트의 번호, j : 주기억장치 블록 번호, v : 캐시 세트들의 수)
- 기억장치 주소 형식
- 태그 필드와 세트 필드를 합한 (t + s) 비트가 주이거장치의 2 ** (t + s)블록들 중의 하나를 지정
- 그 블록이 적재될 수 있는 세트 번호 : 세트 필드에 의해 지정
- 기억장치 주소 형식은 다음과 같다.

- 앞의 [예]에 2-way 세트-연관 사상 방식을 적용하는 경우 주소 형식 : (세트 수 = 8 / 2 = 4개)

아래는 세트-연관 사상 캐시의 조직을 나타내는 그림이다.
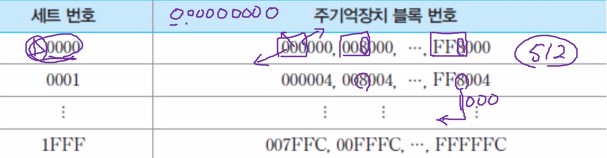
[예]
- 주기억장치 용량 = 128 바이트
- 블록 크기 = 4바이트 ➡️ 주기억장치 블록 수 = 128/4 = 32개
- 캐시 크기 = 32 바이트, 라인 크기 = 4바이트
- 세트당 라인 수 = 2 ➡️ 캐시 내 세트의 수 v = 8/2 = 4개
기억장치 주소 형식

각 세트가 공유하는 주기억장치 블록들 : 512개
64KByte 크기의 2-way 세트-연관 캐시의 예
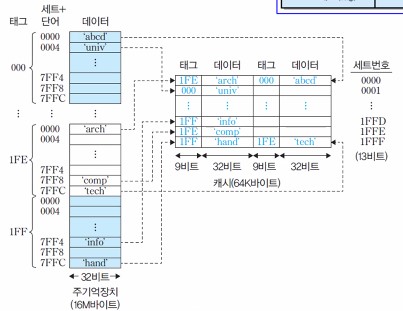
📌 5 - 4. 교체 알고리즘
- 주기억장치로부터 새로운 블록이 캐시로 적재될 때, 만약 모든 라인들이 다른 블록들로 채워져 있다면, 그들(채워진 라인들) 중의 하나를 선택하여 새로운 블록으로 교체
- 교체 알고리즘 : 캐시 적중률을 극대화할 수 있도록 교체할 블록을 선택하기 위한 알고리즘
- 최소 최근 사용(Least Recently Used : LRU) 알고리즘 : 최근에 가장 오래 참조되지 않았던 블록을 교체하는 방식
- 최소 사용 빈도(Least Frequently Used : LFU) 알고리즘 : 참조되었던 횟수가 가장 적은 블록을 교체하는 방식
- FIFO(First-In-First-Out : FIFO) 알고리즘 : 캐시에 적재된 지 가장 오래된 블록을 교체하는 방식
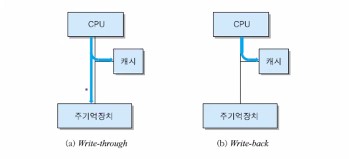
📌 5 - 5. 쓰기 정책
- 캐시의 블록이 변경되었을 때 그 내용을 주기억장치에 갱신하는 시기와 방법의 결정
- Write-through : 모든 쓰기 동작들이 캐시로 뿐만 아니라 주기억장치로도 동시에 수행되는 방식
- [장점] : 캐시에 적재된 블록의 내용과 주기억장치에 있는 그 블록의 내용이 항상 같다.
- [단점] : 모든 쓰기 동작이 주기억장치 쓰기를 포함하므로, 쓰기 시간이 길어진다.
- Write-back : 캐시에서 데이터가 변경되어도 주기억장치에는 갱신되지 않는 방식
- [장점] : 기억장치에 대한 쓰기 동작의 횟수가 최소화되고, 쓰기 시간이 짧아진다.
- [단점] : 캐시의 내용과 주기억장치의 해당 내용이 서로 다르다.
- 블록을 교체할 때는 캐시의 상태를 확인하여 주기억장치에 갱신하는 동작이 선행되어야 하며, 그를 위해서 각 캐시 라인이 상태 비트를 가지고 있어야 한다.
- Write-through : 모든 쓰기 동작들이 캐시로 뿐만 아니라 주기억장치로도 동시에 수행되는 방식
다음은 쓰기 정책에 따른 쓰기 동작의 비교를 나타내는 그림이다.
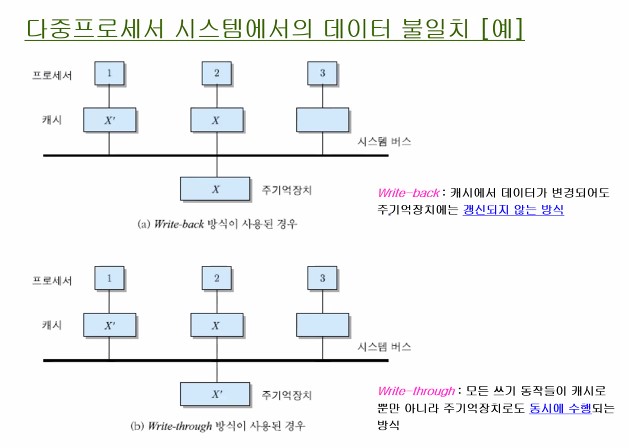
다중프로세서 시스템에서의 데이터 불일치 문제
- 다중프로세서 시스템에서의 데이터 불일치 문제 : 주기억장치에 있는 블록의 내용과 캐시 라인에 적재된 블록의 내용이 서로 달라지는 문제
- 캐시 일관성 프로토콜 필요 [예) MESI 프로토콜]
아래는 다중프로세서 시스템에서의 데이터 불일치를 나타내는 그림이다.
📌 5 - 6. 다중 캐시
- 온-칩 캐시 : 캐시 액세스 시간을 단축시키기 위하여 CPU 칩 내에 포함시킨 캐시 (아래 그림의 L1)
- 계층적 캐시
- 온-칩 캐시를 1차(L1) 캐시로 사용하고, 칩 외부에 더 큰 용량의 2차(L2) 캐시를 설치하는 방식
- L2는 L1의 슈퍼-세트 : L2의 용량이 L1보다 크며, L1의 모든 내용이 L2에도 존재
- 먼저 L1을 검사하고, 만약 원하는 정보가 L1에 없다면 L2를 검사하며, L2에도 없는 경우에는 주기억장치를 액세스
- L1은 속도가 빠르지만, 용량이 작기 때문에 L2 보다 적중률은 더 낮다
- 2-단계 캐시 시스템의 평균 기억장치 액세스 시간 :
- 만약, H2가 전체 기억장치 액세스들에 대한 L2의 적중률이라면, Ta = H1 x TL1 + (H2 - H1) x TL2 + (1 - H2) x Tm
- 만약, H2가 L1에서 미스된 액세스들에 대한 L2의 적중률이라면, Ta = H1 x TL1 + (1 - H1) H2 x TL2 + {1 - H1 - (1 - H1)H2 x Tm}
- 계층적 캐시
아래는 계층적 캐시를 나타내는 그림이다.
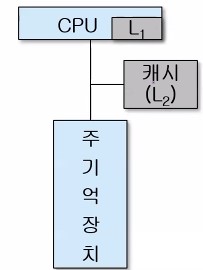
- 온-칩 캐시
- (2. 분리 캐시)
- 캐시를 명령어 캐시와 데이터 캐시로 분리
- 명령어 인출 유니트와 실행 유니트 간의 캐시 액세스 충돌 제거
- 대부분의 고속 프로세서들에서 사용
- (2. 분리 캐시)
아래는 분리 캐시의 한 사례(PowerPC 620 프로세서)를 나타내는 그림이다.
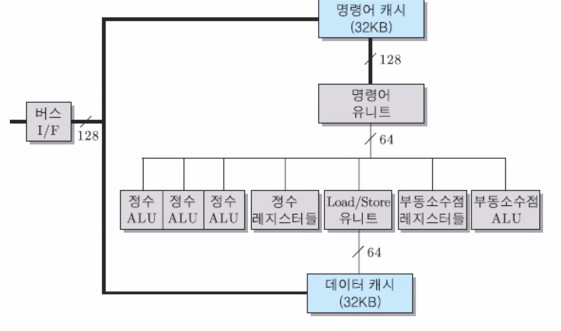
아래는 계층적 분리 캐시(계층 + 분리)의 사례(인텔 이타늄 프로세서)를 나타내는 그림이다.
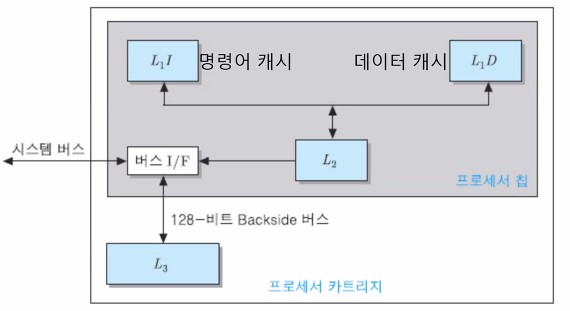
아래는 멀티-코어 프로세서(인텔 i7-990X 쿼드-코어)의 캐시 구조를 나타내는 그림이다.
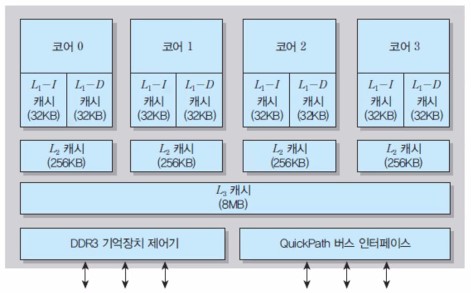
🎯 6. DDR SDRAM
최신 기억장치 기술
- 기억장치의 액세스 속도는 CPU에 비하여 현저히 낮음
- 동영상 편집, 음성 / 영상 압축과 같은 대규모 데이터 처리
📌 6 - 1. SDRAM
- 동기식 DRAM (Synchronous DRAM : SDRAM) : 액세스 동작이 시스템 클록에 맞추어(동기화 되어) 수행되는 DRAM
- [예] 읽기 동작
- CPU는 한 클록 주기 동안에 시스템 버스를 통하여 주소와 읽기 신호를 기억장치로 보낸 후, 그 결과를 기다리지 않고 내부적으로 다른 연산을 수행
- SDRAM은 주소와 읽기 신호를 받은 즉시 읽기 동작을 시작하며, 그 동작이 완료되면 시스템 버스 사용권을 획득한 후, 다음 클록주기동안 버스를 통하여 CPU로 데이터 전송
- CPU는 그 데이터를 받아서, 다음 연산을 수행
SDRAM의 내부 조직
- 다수의 뱅크들로 구성 : 뱅크별로 동시 액세스 가능
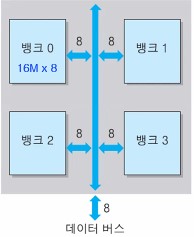
- [예] 512Mbit(64MByte) SDRAM
- 4개의 16M x 8bit 뱅크들로 구성 : 4 x 16MByte = 64MByte
- 주소 비트 수 = 26, 최상위 2 비트 : 뱅크 선택에 사용
아래는 네 개의 뱅크들로 구성된 SDRAM을 나타내는 그림이다.
아래는 각 뱅크의 내부 조직을 나타내는 그림이다.
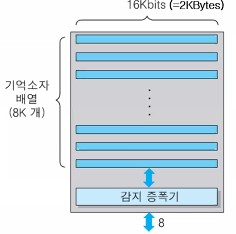
행 : 8K개의 기억소자 배열
각 열에는 16Kbit (2KByte) 씩 저장 ➡️ 행 주소 = 13비트, 열 주소 = 11비트
칩의 입출력(데이터) 선의 수 : 8
각 읽기 동작 시, 배열의 데이터(2KByte) 전체가 감지 증폭기로 이동 = 행 열기
그런 다음, 열 주소에 의해 바이트 단위로 데이터 버스에 실림
버스트 모드 : 여러 바이트들을 연속적으로 전송하는 동작
버스트 길이 : 각 버스트 동작 동안에 전송되는 데이터 바이트들의 수
아래는 버스트 읽기 동작의 타이밍 도 (버스트 길이 = 4)를 나타내는 그림이다.
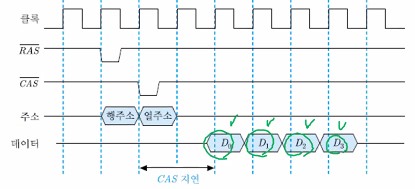
CAS 지연 : CAS 신호와 열 주소가 들어온 순간부터 데이터가 인출되어 버스에 실릴 때까지의 시간
버스트 모드의 효과 : 버스 사용권을 한 번획득한 후, 여러 클록동안 연속 전송 가능
기억장치 모듈 구성의 필요성
- SDRAM의 데이터 입출력 폭 = 8비트
- 단어 단위의 데이터 액세스를 위하여 여러 개의 SDRAM 칩들을 병렬로 접속하여 기억장치 모듈을 구성
- [예] 64-비트 컴퓨터 시스템을 위한 기억장치 모듈
- 8개의 64M x 8bit SDRAM 칩들을 병렬접속 ➡️ 64비트씩 읽기 / 쓰기 가능한 512MByte 기억장치 모듈
기억장치 모듈 당 SDRAM 칩 한 개를 추가 ➡️ 8-비트 길이의 ECC(error-correction code)를 같이 저장
📌 6 - 2. DDR SDRAM
기억장치 모듈의 대역폭을 향상시키기 위한 기술
대역폭 : 단위 시간 당 전송되는 데이터 량, 단위 : [bytes/sec]
DDR(double data rate) SDRAM : 버스 클록 당 두 번의 데이터 전송 (클록 펄스의 상승-에지 및 하강-에지에서 각각 전송)
(SDRAM : SDR(single data rate) SDRAM이라 부름)
DDR2 SDRAM : DDR SDRAM과 같으며, 버스 클록 주파수를 두 배로 높여 대역폭 향상
아래 그림은 DDR SDRAM 읽기 동작의 타이밍(버스트 길이 = 8)을 나타내는 그림이다.
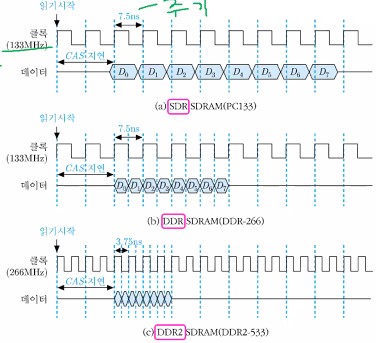
읽기 시간 비교 (예 : 버스트 길이 = 8)
- SDR @ 133MHz [PC133]
- 버스 클록 = 133MHz
- 매 클록 주기(7.5ns)마다 64비트씩 전송
- 8번의 데이터 전송에 걸리는 시간 = CAS 지연(15ns) + 7.5ns x 8 = 75ns
- DDR @ 133 MHz [DDR-266]
- 상승 및 하강 에지(3.75ns)마다 64비트씩 전송
- 8번의 데이터 전송에 걸리는 시간 = CAS 지연(15ns) + 3.75ns x 8 = 45ns
- DDR-2 @ 266 MHz [DDR-533]
- 버스 클록 = 266 MHz
- 상승 및 하강 에지(1.875ns)마다 64비트씩 전송
- 8번의 데이터 전송에 걸리는 시간 = CAS 지연(15ns) + 1.875nx x 8 = 30ns
- 읽기 시간 (CAS 지연 제외) 비고 :
- 60ns (SDR) ➡️ 30ns (DDR) ➡️ 15ns (DDR-2)
DDR 기술의 기본 원리
- 버스 클록의 상승 에지와 하강 에지에서 각각 데이터 전송
- 기억장치 제어기 및 버스 인터페이스 회로의 개선을 통하여 버스 클록 주파수 향상
- DDR3 및 DDR4도 같은 원리를 적용하여 설계
CAS 지연
- DDR : SDRAM 칩의 CAS 지연 = 15ns일 때, 클록 주기가 7.5ns이므로, CAS 지연 = 2주기
- DDR2 : f = 266MHz (클록 주기 = 3.75ns) ➡️ CAS 지연 = 4주기 (15ns / 3.75 = 4주기)
- DDR3 및 DDR4에 사용되는 SDRAM 칩들의 CAS 지연 = 10ns
- DDR3-1600 @800MHz : CAS 지연 = 8주기
- DDR4-3600 @1800MHz : CAS 지연 = 16주기
📌 6 - 3. 기억장치 랭크
데이터 입출력 폭이 64비트가 되도록 구성한 기억장치 모듈 (다수의 기억장치 칩들로 구성)
기억장치 산업표준그룹인 JEDEC에 의해 정의됨
x4 혹은 x8 조직의 칩들을 여러 개 사용하여 데이터 입출력 폭이 64비트가 되도록 함
기억장치 모듈은 주 기판의 기억장치 슬록에 장착
- 단면 모듈 : 기판의 한 명에만 칩들을 장착하며, 접속 핀들도 한 면에만 설치하거나 양면에 중복적으로 설치 - SIMM(single in-line memory module)이라고도 부름
- 양면 모듈 : 기판의 양 면에 칩들을 장착하며, 접속 핀들도 양면에 설치하여 많은 신호 입출력 가능 - DIMM(double in-line memory module)이라고도 부름
단일-랭크 모듈 : x8 조직의 SDRAM 8개를 병렬 접속하여 하나의 랭크를 구성함으로써, 64비트 데이터가 한 번에 버스를 통하여 전송되도록 구성한 기억장치 모듈
'Computer Science > 컴퓨터 구조' 카테고리의 다른 글
| [컴퓨터 구조] - 보조저장장치 (0) | 2023.11.28 |
|---|---|
| [컴퓨터 구조] - 제어 유니트 (1) | 2023.10.30 |
| [컴퓨터 구조] - 컴퓨터 산술과 논리 연산 (0) | 2023.10.08 |
| [컴퓨터 구조] - CPU의 구조와 기능 (1) | 2023.10.07 |
| [컴퓨터 구조] - 컴퓨터 시스템 개요 (1) | 2023.10.05 |



